Java Native Access Performance

This is a remake of java-native-benchmark: performance benchmark of different ways (libraries) of using native libraries. The original benchmark was created for Windows, and I’m more interested in Linux. I tried to fork the original repo, but I failed to make gradle work with IntelliJ, so I created with in my own bazel (ironical, yes) repo.
In the nearest future I’m going to run a more sophisticated benchmark for native calls.
What Are We Benchmarking?
In the original benchmark function GetSystemTime from Windows API was called. On Linux I decided to go with the simpler one: getloadavg from libc.
Tested libraries:
- JNI: Java’s standard native interop mechanism.
- JNA
- BridJ
- JNR-FFI
- JavaCPP
- “Pure” Java: getting load average via JMX.
I didn’t use Panama as it requires too much of an effort. If you’re interested, there is a very good long tutorial.
Benchmarks
Benchmark is very simple and straight-forward. The fastest access is via JNI, JNR and JavaCPP. Interestingly enough, JMX is slower than JNI, which is a little bit unexpected.
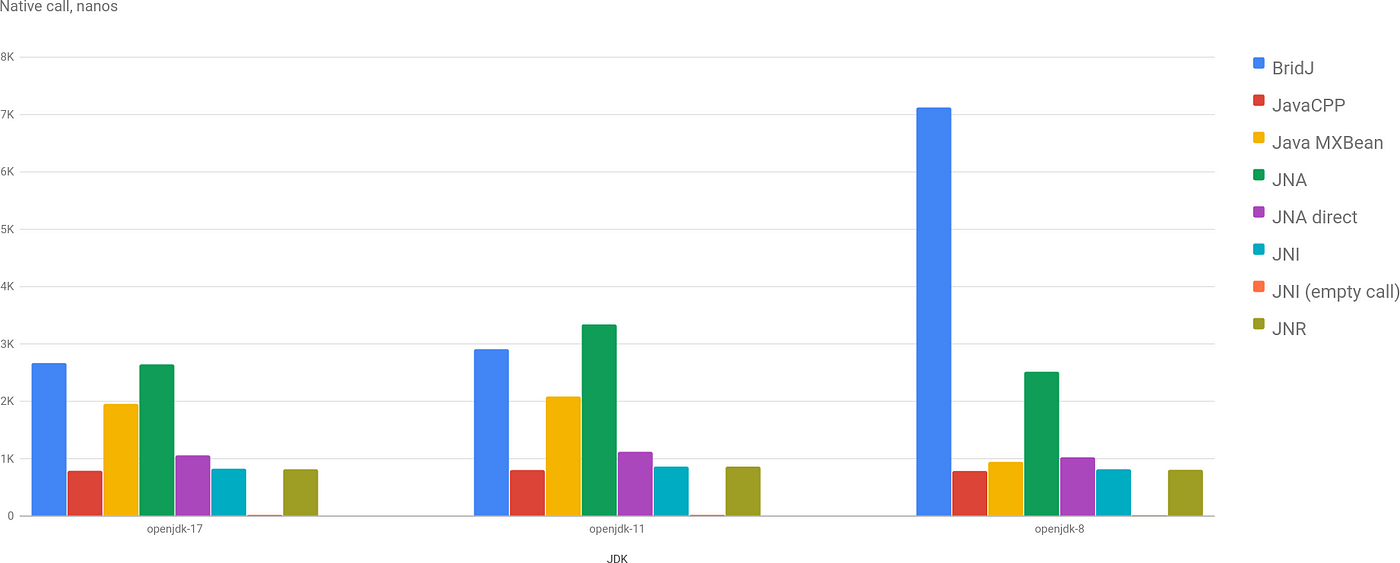
JNI empty just shows a baseline, which is about 22 nanoseconds on my laptop. Seemingly, not a huge overhead (for a simple function that takes int and returns it back).
However, if we will compare it with a native benchmark, in which getloadavg takes approximately 470 nanoseconds. Then the actual overhead in this scenario vs the best result of 794 nanoseconds would be 300+ nanoseconds.
Conclusion
A call to a native library is not cheap. But still might be beneficial comparing to JDK in terms of performance. JNI has a similar performance to JNR-FFI and JavaCPP, but requires to write a native library using jni.h or jni crate for Rust.
