MySQL as Redis vs Redis?

This is the next portion of my “research” around my UUID set cache. I’ve benchmarked Map Performance Java vs Scala, binary search instead of HashSet and even moving Set cache to Redis. Now it’s time to benchmark MySQL as such cache.
This is a silly benchmark, I know. But just for the whole picture :) Hope I’m not going to benchmark other out-of-process stuff with it.
However, I decided to test one more thing, related to JDBC, that I wanted to benchmark for a while, but didn’t have a good justification to actually spend time on it. Keep on reading!
What are we testing?
My use case is simple — I have a large in-memory set of UUID, around 1 million keys. This is how I’m going to store it in MySQL:
CREATE TABLE set1m (
id BINARY(16) NOT NULL PRIMARY KEY
) ENGINE=InnoDB ROW_FORMAT=DYNAMIC;A code to convert UUID to BINARY(16) (which is just an array of bytes in JDBC):
public static byte[] toBytes(UUID value) {
byte[] array = new byte[16];
ByteBuffer bb = ByteBuffer.wrap(array);
bb.putLong(value.getMostSignificantBits());
bb.putLong(value.getLeastSignificantBits());
return array;
}Benchmark
Benchmark code is relatively simple: N threads take UUIDs one by one and make a simple query:
SELECT 1 FROM set1m WHERE id = ?I benchmarked for one thread to 10 threads.
Spice It Up!
I was wondering about the overhead of connection pools for a while. At Wix we started to use HikariCP a while ago. We discussed it with a friend, and he claimed that it’s not smart to use connection pools in blocking environment, that you can simply use thread locals with connections and some housekeeping and it would be much more efficient.
There are some problems with this approach, of course:
- If Jetty (or any other servlet container) uses all its threads from the pool, then we would be using more connections than we actually should.
- Housekeeping is tricky. Also it’s impossible to warm-up connections or at least not simple (issue HTTP calls on startup?)
Anyway, in the benchmark it’s a nice opportunity to actually check it without writing complex code for housekeeping of connections and such. So, this is what I did: compared HikariCP with pre-warmed up connections versus pre-warmed up connections stored in ThreadLocal.
Results
Median query time doesn’t really depend on table size. However, 10M table is slightly slower (few microseconds):
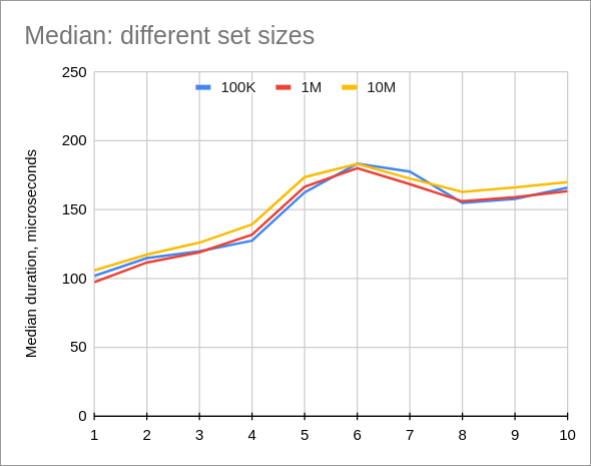
On the contrary, maximum query time seem to depend a bit on a table size. I’m wondering why? I set innodb_buffer_pool_size to 1G, which is larger than table size.

HikariCP vs Thread Local
Median time is consistently better for Thread Local, 3–8 microseconds difference. This is about 10% for querying localhost, but usually we query MySQL over the network, so it would be 1% or less of the overhead. Not great, not terrible.

MySQL vs Redis
Predictably, Redis has better performance than MySQL. Even though data set in MySQL is really small (hundreds of megabytes), overhead of SQL seems to be too significant.
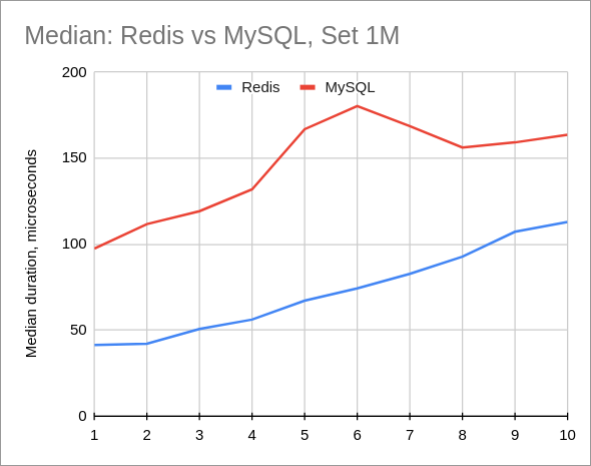
And if we look at the maximum request duration, it’s even worse. Meaning that MySQL consumes much more CPU than Redis:
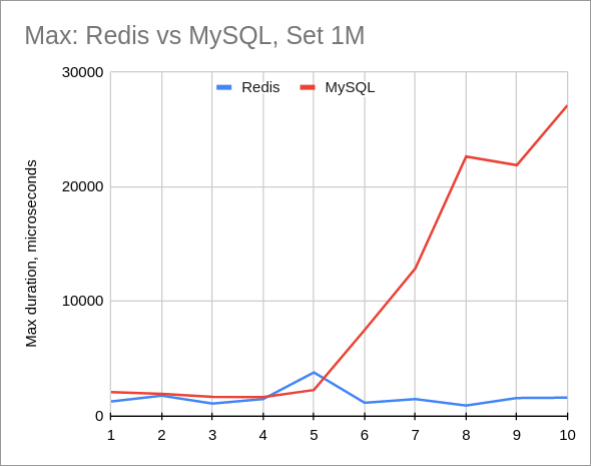
Conclusion
For sure, MySQL doesn’t fit this use case at all. It makes a lot of sense, the strength of MySQL isn’t here, but in stability, replication, transactions and many more.
It was fun (as usual) to benchmark different aspects of MySQL. I also happy that I don’t need to write housekeeping code for thread local connection pool to benchmark it (I guess it was more than 4 years in my backlog), because I’d rather explore async access to MySQL and not blocking.
Full data and charts for MySQL and MySQL vs Redis. Source code is on GitHub.
